
Information Retrieval: La Scienza Nascosta Dietro Ogni Tua Ricerca Online
 Quando interroghi Google, cerchi un’email nel tuo archivio, filtri prodotti su Amazon o scegli un film su Netflix, stai interagendo — spesso senza saperlo — con un sistema di Information Retrieval (IR). Il concetto di base è di una semplicità disarmante: hai a disposizione una mole gigantesca di contenuti, poni una domanda (spesso vaga o “imperfetta”) e desideri trovare rapidamente e con precisione ciò che ti serve. Ma dietro questa apparente semplicità si cela una disciplina informatica complessa e affascinante, che ha letteralmente modellato il nostro accesso alla conoscenza.
Quando interroghi Google, cerchi un’email nel tuo archivio, filtri prodotti su Amazon o scegli un film su Netflix, stai interagendo — spesso senza saperlo — con un sistema di Information Retrieval (IR). Il concetto di base è di una semplicità disarmante: hai a disposizione una mole gigantesca di contenuti, poni una domanda (spesso vaga o “imperfetta”) e desideri trovare rapidamente e con precisione ciò che ti serve. Ma dietro questa apparente semplicità si cela una disciplina informatica complessa e affascinante, che ha letteralmente modellato il nostro accesso alla conoscenza.
Questo articolo è il punto di partenza per un viaggio nel cuore del recupero dell’informazione. Non ci limiteremo a definire cos’è, ma esploreremo perché è diventato il motore invisibile del web e come la sua evoluzione, spinta dai Big Data, abbia reso possibili le tecnologie che usiamo ogni giorno.
1.1 Cos’è l’Information Retrieval: Dalla Parola alla Rilevanza
L’Information Retrieval (IR), o recupero dell’informazione, è la disciplina che si occupa di organizzare, rappresentare, ricercare e ordinare contenuti prevalentemente non strutturati. Il suo scopo non è semplicemente “trovare parole”, ma estrarre significato e rilevanza da una massa informe di dati.
Definizione Operativa: L’IR è l’insieme di tecniche e modelli matematici che permettono di interrogare una vasta collezione di documenti per ottenere un sottoinsieme di essi, ordinato per pertinenza decrescente rispetto alla necessità informativa dell’utente.
Il punto cruciale è proprio la rilevanza. Un sistema di IR non si limita a verificare la presenza di una keyword; il suo vero obiettivo è interpretare l’intento dietro la ricerca e restituire risorse che lo soddisfino pienamente.
Esempio Pratico: Una Ricerca Locale a Roma
Prendiamo la query: ristorante carbonara centro storico Roma.
- Ricerca basilare (keyword matching): Il sistema restituisce tutte le pagine che contengono le parole “ristorante”, “carbonara”, “centro”, “storico” e “Roma”. Il risultato è un elenco caotico di blog, recensioni datate, forse persino articoli di cronaca.
- Ricerca basata sulla rilevanza (IR): Un sistema evoluto comprende l’intento: l’utente vuole mangiare una buona carbonara, ora o a breve, in una specifica area geografica. Darà pertanto priorità a ristoranti con recensioni recenti, schede Google My Business geolocalizzate nel centro di Roma e siti web che menzionano la carbonara nel menu online.
Questa distinzione segna il passaggio da una ricerca meccanica a una ricerca “intelligente”, resa possibile dalla capacità del sistema di gestire la natura complessa dei dati digitali.
La Differenza Fondamentale: Dati Strutturati vs. Non Strutturati
La necessità stessa dell’Information Retrieval nasce dalla distinzione tra due macro-categorie di dati.
Dati Strutturati: L’Ordine del Database Relazionale
I dati strutturati sono informazioni organizzate in tabelle rigide, con colonne e tipi di dato predefiniti (numeri, date, stringhe fisse). Ogni dato ha una sua “casella” precisa, governata da uno schema. I database SQL ne sono l’esempio perfetto.
| id_prodotto | nome_prodotto | prezzo | categoria | disponibile_ecommerce |
|---|---|---|---|---|
| 101 | Scarpa da Corsa XYZ | 129,99 € | Calzature Sportive | VERO |
| 102 | T-shirt Tecnica | 39,99 € | Abbigliamento | VERO |
| 103 | Orologio GPS | 249,50 € | Elettronica | FALSO |
Le interrogazioni su questi dati sono precise e matematiche: SELECT * FROM prodotti WHERE prezzo < 50. Il sistema non interpreta: filtra dati esatti. Il limite? Se l’informazione non è incasellata in una colonna, semplicemente non esiste per il database.
Dati Non Strutturati: Il Dominio dell’IR
I dati non strutturati rappresentano la stragrande maggioranza del patrimonio informativo digitale. Sono contenuti in cui l’informazione è immersa nel testo, nell’audio, nelle immagini, senza uno schema fisso. Esempi concreti includono articoli di blog, PDF di report, recensioni di prodotti, corrispondenza email, descrizioni di video su YouTube e contenuti dei social media.
Qui, le domande degli utenti sono intrinsecamente ambigue e richiedono interpretazione: migliori strategie per link building nel 2026, oppure come impermeabilizzare un terrazzo a Napoli. Per rispondere, un sistema di recupero dell’informazione deve comprendere sinonimi (terrazzo vs balcone), relazioni semantiche (impermeabilizzare e infiltrazioni) e soprattutto deve ordinare (rankare) i risultati, perché quasi mai esiste un’unica risposta “giusta”.
In sintesi: Mentre i database tradizionali eccellono nel trovare dati esatti in campi predefiniti, l’Information Retrieval è la tecnologia che ci permette di scoprire conoscenza all’interno del caos apparente del testo libero. È il ponte tra una domanda umana e un archivio digitale.
 1.2 L’Impatto dei Big Data: Perché l’IR è Diventato Essenziale
1.2 L’Impatto dei Big Data: Perché l’IR è Diventato Essenziale
Per decenni, il recupero dell’informazione è stato un campo di nicchia per bibliotecari e accademici. L’esplosione dei Big Data lo ha trasformato in una necessità ingegneristica fondamentale. Il problema è semplice da enunciare: possediamo una quantità di dati che cresce in modo esponenziale, ma la nostra capacità di analizzarli con metodi tradizionali è rimasta drammaticamente indietro.
Questo divario è spiegato dall’evoluzione asimmetrica di tre fattori tecnologici chiave: capacità, throughput e latenza.
1. Capacità di Memorizzazione
La capacità di storage (dischi rigidi, SSD, cloud) è cresciuta a un ritmo vertiginoso. Oggi, archiviare terabyte o petabyte di dati è tecnicamente ed economicamente fattibile per molte organizzazioni. Un’azienda di medie dimensioni può conservare anni di email, contratti in PDF, log di server e registrazioni di video-call. Tutto è “salvato”, ma questo non significa che sia accessibile o utile.
2. Throughput (Velocità di Trasferimento)
Il throughput misura la quantità di dati che un sistema può leggere o scrivere in un dato intervallo di tempo (es. MB/s o GB/s). Sebbene anche questa metrica sia migliorata, non ha tenuto il passo con l’aumento della capacità. È come avere una biblioteca grande quanto una città, ma poter leggere solo una pagina al secondo: teoricamente hai accesso a tutto, ma scansionare l’intera raccolta per trovare un’informazione richiederebbe anni.
3. Latenza (Tempo di Risposta)
La latenza è il tempo necessario per iniziare una singola operazione di lettura. Le operazioni in RAM sono quasi istantanee (nanosecondi), ma accedere a un dato su disco rigido o attraverso una rete richiede tempi molto più lunghi (millisecondi). Un approccio “ingenuo” che apre e controlla ogni singolo file genera un numero enorme di operazioni di lettura sparse: la somma di queste piccole latenze rende la ricerca intollerabilmente lenta, anche se il throughput teorico del disco è elevato.
Il Divario che Impone un Cambio di Paradigma
Il problema fondamentale è che la capacità di archiviazione è cresciuta molto più velocemente della nostra capacità di scansione sequenziale. Cercare un termine in 1.000 documenti è fattibile. In un milione è lento. In un miliardo è semplicemente impossibile in tempi utili per un’applicazione interattiva.
La soluzione dell’IR: Spostare il carico computazionale “offline” per rendere la ricerca “online” quasi istantanea.
Invece di scansionare tutto al momento della richiesta, un sistema IR esegue un processo di preparazione chiamato indicizzazione. Durante questa fase, il sistema analizza tutti i documenti e costruisce una struttura dati ottimizzata: l’indice inverso (inverted index). Questo indice è, in sostanza, un dizionario di tutti i termini presenti nei documenti, dove ogni termine è associato a una lista degli ID dei documenti che lo contengono.
Esempio Concreto: Ricerca su un Blog di Edilizia
- Senza Indice (Approccio Naive): Per la query problemi infiltrazioni lastrico solare, il sistema dovrebbe aprire e leggere ogni singolo articolo del blog. Se il blog ha migliaia di articoli, l’operazione richiederebbe secondi o minuti.
- Con Indice Inverso (Approccio IR): Il sistema consulta l’indice, trova le liste dei documenti che contengono “infiltrazioni”, “lastrico” e “solare”, le interseca e identifica in pochi istanti un piccolo insieme di candidati pertinenti. La risposta arriva in millisecondi.
L’Information Retrieval non è quindi un lusso, ma una risposta ingegneristica a un limite fisico: il tempo. È la tecnologia che ci permette di trovare un ago in un pagliaio di dimensioni planetarie, e di farlo prima che l’utente perda la pazienza.
 1.3 Breve Storia dei Sistemi di Ricerca: Dall’Argilla al Cloud
1.3 Breve Storia dei Sistemi di Ricerca: Dall’Argilla al Cloud
L’esigenza di recuperare informazioni è antica quanto la scrittura. Ciò che è cambiato sono gli strumenti e la scala, ma la filosofia di fondo è rimasta sorprendentemente simile: creare rappresentazioni astratte dei contenuti per potervi accedere in modo efficiente.
Le Origini: Metadati Ante Litteram
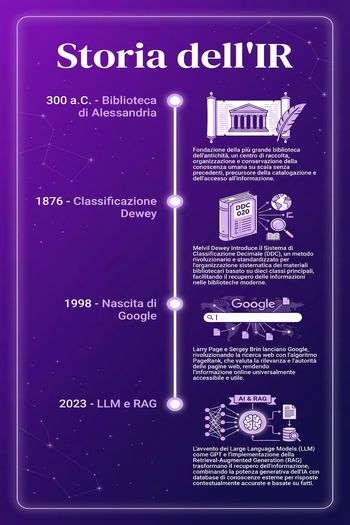
Nelle grandi biblioteche dell’antichità, come la leggendaria Biblioteca di Alessandria, i bibliotecari affrontavano un problema familiare: migliaia di rotoli di papiro. Come trovare un’opera specifica senza srotolarli tutti? La soluzione fu la creazione di metadati: cataloghi (i Pinakes di Callimaco) che descrivevano le opere per titolo, autore e argomento. Non si cercava dentro il contenuto, ma nella sua rappresentazione. Questo è il principio fondante di ogni sistema di indicizzazione.
L’Era della Classificazione: L’Ordine di Dewey
Un balzo fondamentale fu l’introduzione di sistemi di classificazione gerarchica, come la Classificazione Decimale Dewey nel 1876. Dewey non si limitò a etichettare i libri; creò un sistema numerico che posizionava ogni opera all’interno di un albero della conoscenza. Un libro con codice 510 (Matematica) si trovava fisicamente vicino a uno con codice 530 (Fisica), riflettendo una prossimità concettuale. Sebbene non fosse una ricerca per query, introduceva un’idea potente: la navigazione strutturata come strumento di scoperta.
La Rivoluzione Informatica: Dalla Corrispondenza Esatta alla Rilevanza
Con l’avvento dei computer, la ricerca si biforcò. Da un lato, i database relazionali perfezionarono la ricerca su dati strutturati. Dall’altro, la gestione dei documenti testuali diede vita al campo moderno dell’Information Retrieval. I primi sistemi commerciali (anni ’70 e ’80) erano basati su modelli booleani: permettevano di combinare parole chiave con operatori logici (AND, OR, NOT). Erano potenti ma rigidi, e richiedevano utenti esperti per formulare query efficaci.
Il vero cambiamento avvenne con l’introduzione del concetto di ranking.
L’idea rivoluzionaria fu che non era sufficiente trovare i documenti che contenevano le parole chiave. Era necessario ordinarli in base a una stima della loro utilità per l’utente.
Nacquero così algoritmi come il TF-IDF (Term Frequency–Inverse Document Frequency), che pesavano l’importanza di un termine in un documento in relazione alla sua frequenza nell’intera collezione. Un termine raro presente molte volte in un documento era un segnale di rilevanza molto più forte di un termine comune (come “e” o “il”) presente ovunque.
Google e il Web: La Rilevanza su Scala Planetaria
L’esplosione del World Wide Web presentò due sfide inedite: una scala mai vista prima (miliardi di documenti) e una nuova struttura: i link ipertestuali. I fondatori di Google intuirono che questi link erano un segnale di autorevolezza. Un link da una pagina A a una pagina B poteva essere interpretato come un “voto” di A verso B.
L’algoritmo PageRank fu rivoluzionario perché calcolava la popolarità di una pagina basandosi non solo su quanti link riceveva, ma anche sulla popolarità delle pagine da cui li riceveva. Google combinò questa analisi della struttura del web con le consolidate tecniche di analisi testuale dell’IR, creando un motore di ricerca di qualità senza precedenti. Il motore moderno orchestra decine di segnali per il ranking:
- Analisi del contenuto: Rilevanza testuale, semantica, freschezza.
- Analisi dei link: Autorevolezza, trust, anchor text.
- Contesto dell’utente: Posizione geografica (GEO), lingua, cronologia delle ricerche.
- Interazione utente: Click-through rate, tempo sulla pagina, segnali di soddisfazione.
L’Era degli LLM: Dalla Lista di Link alla Risposta Diretta
L’avvento dei Large Language Models (LLM) sta segnando un’altra trasformazione. L’interfaccia di ricerca sta evolvendo: sempre più spesso, gli utenti non desiderano una lista di 10 link, ma una risposta sintetica e diretta alla loro domanda. Questo non rende obsoleto l’Information Retrieval; al contrario, lo rende ancora più cruciale.
Un LLM lasciato a sé stesso può “allucinare”, inventando fatti non supportati da alcuna fonte. La soluzione è un’architettura nota come Retrieval-Augmented Generation (RAG):
- Recupero (Retrieval): La domanda dell’utente viene prima inviata a un sistema di IR (spesso ibrido, che combina ricerca per keyword e ricerca semantica tramite embeddings) per trovare i documenti più pertinenti da fonti affidabili.
- Generazione (Generation): Il testo recuperato viene fornito all’LLM come contesto, con l’istruzione di formulare una risposta basandosi esclusivamente su quelle informazioni.
In questo scenario, la qualità della fase di recupero determina la qualità e l’affidabilità della risposta finale. Se il sistema di IR fallisce, l’LLM, per quanto eloquente, produrrà una risposta errata o incompleta. L’IR rimane il fondamento su cui poggia la ricerca di conoscenza, anche nell’era dell’intelligenza artificiale generativa.
1.4 Capire la Scala: Dai Terabyte ai Quettabyte e l’Impatto sulle Strategie
Parlare di Big Data senza comprendere gli ordini di grandezza è come parlare di astronomia senza distinguere tra un pianeta e una galassia. I prefissi come tera, peta ed exa non sono solo etichette astratte; rappresentano soglie oltre le quali le strategie di gestione e analisi dei dati devono cambiare radicalmente.
Una Gerarchia di Grandezze in Termini Umani
- Byte: Un singolo carattere di testo.
- Kilobyte (KB): Un’email di solo testo.
- Megabyte (MB): Una fotografia ad alta risoluzione o un breve brano musicale in MP3.
- Gigabyte (GB): Un film in streaming ad alta definizione.
- Terabyte (TB): L’intero contenuto del disco rigido di un laptop moderno. Un singolo TB può contenere circa 250.000 foto o 500 ore di video HD.
Fino a qui, siamo nel campo dei “dati grandi”, gestibili con strumenti relativamente standard. È salendo oltre che entriamo nel vero dominio dei Big Data.
Nota Tecnica: In informatica, si distingue tra prefissi decimali (base 1000, es. KB, MB, GB) e prefissi binari (base 1024, es. KiB, MiB, GiB). Per una discussione strategica sull’IR, la differenza è trascurabile. Ciò che conta è il salto di scala.
La Scala Esponenziale dei Prefissi Superiori
Ogni passo nella gerarchia dei prefissi rappresenta un aumento di un fattore 1.000.
| Prefisso | Simbolo | Potenza di 10 | Equivalente in TB | Esempio di Scala |
|---|---|---|---|---|
| Terabyte | TB | 10¹² | 1 | Dati personali, piccole aziende |
| Petabyte | PB | 10¹⁵ | 1.000 | Data center di grandi aziende, genomica |
| Exabyte | EB | 10¹⁸ | 1.000.000 | Traffico internet globale mensile |
| Zettabyte | ZB | 10²¹ | 1.000.000.000 | L’intera “sfera digitale” globale |
| Ronnabyte | RB | 10²⁷ | — | Prefisso ufficiale per necessità future |
| Quettabyte | QB | 10³⁰ | — | Prefisso ufficiale per necessità future |
Passare da Terabyte a Petabyte non significa avere “un po’ più di dati”. Significa avere mille volte più dati. Questo salto di scala rompe gli approcci tradizionali.
Perché la Scala Obbliga all’Information Retrieval
Immaginiamo di voler trovare un’informazione con l’approccio “forza bruta”: scansionare tutto il contenuto. Vediamo come questa strategia fallisce miseramente all’aumentare della scala.
1. Esplosione del Tempo di Scansione
Se un moderno sistema di storage impiega, poniamo, 1 ora per leggere sequenzialmente 1 TB di dati, per leggere 1 PB impiegherebbe 1.000 ore (circa 42 giorni). Per 1 EB, si parlerebbe di oltre 114 anni. È evidente che la scansione completa non è un’opzione praticabile per rispondere a una query in tempo reale.
2. I Costi Nascosti: Latenza e Accesso Casuale
Su larga scala, il throughput diventa meno importante del numero di accessi e della latenza di ciascuno. Un sistema che deve “saltare” continuamente tra file e blocchi di dati diversi per rispondere a una query sta sprecando la maggior parte del suo tempo non a leggere dati, ma ad aspettare di poterli leggere. I sistemi di IR, tramite gli indici, sono progettati per minimizzare questo “saltellare”, trasformando una miriade di letture casuali e lente in poche letture sequenziali e veloci.
3. La Necessità Assoluta di Pre-Calcolo: L’Indicizzazione
Si chiude così il cerchio. Poiché la ricerca “al volo” è impossibile su scala, l’unica strategia vincente è investire tempo e risorse computazionali in anticipo per creare strutture dati che rendano la ricerca successiva estremamente efficiente. L’indicizzazione è questo: il processo di pre-calcolo che analizza e mappa l’intera collezione di documenti per costruire l’indice inverso.
Esempio Finale: Da un Archivio Cartaceo a un Data Lake
Immaginiamo un archivio di 10 milioni di documenti legali (circa 50 TB). Cercare il termine clausola risolutiva espressa contratto di fornitura senza un indice richiederebbe di aprire e analizzare con OCR ogni singolo documento: un’operazione che potrebbe durare settimane. Con un indice inverso, il sistema ha già mappato dove si trovano i termini rilevanti. Intersecando le liste di documenti, identifica in pochi millisecondi un piccolo insieme di candidati altamente pertinenti, che vengono poi ordinati e presentati all’utente.
Concetto Chiave da Ricordare: I Big Data non sono solo “tanti dati”. Sono una quantità di dati tale da imporre un cambiamento di strategia. L’approccio a forza bruta cessa di essere una soluzione e l’Information Retrieval, con le sue tecniche di indicizzazione e ranking, diventa l’unica via percorribile per estrarre valore da questa immensa risorsa.
Nel prossimo articolo, passeremo dalla teoria alla pratica, analizzando il primo modello operativo dell’IR: il modello Booleano e la costruzione passo-passo di un indice inverso.